Adventure through the world of DOM: A detailed journey from basic understanding of selectors to mastery in manipulating web content and styles
By Erick Gutierrez
6 min read | September 19, 2023
In the digital age, web scraping has become an essential tool for extracting valuable information from the web. However, the heart of any scraping project lies in the ability to select and extract specific data from a webpage. In this article, Bitmaker will guide you through the world of selectors, which are crucial for navigating the DOM and accurately extracting data.
Introduction
The Document Object Model (DOM) is the underlying structure behind every web page we visit. It is a structured and hierarchical representation of all the elements and content of a website. Imagine the DOM as a lush tree: each branch represents an element, like a div or an image, and each leaf is data, such as text or a link.
Navigating through this tree to find and extract specific information can be a challenge. This is where selectors become our compass. These tools allow us to specify and locate precise data within the vast framework of the DOM, making web scraping easier and ensuring that we get exactly what we’re looking for.
Types of Selectors and Their Significance
-
CSS Selectors: These selectors are based on the structure and style of the DOM. They are widely used due to their simplicity and efficiency. Example: div.content > p:first-child selects the first paragraph within a div with the class “content.”
-
XPath: It’s a more complex but powerful syntax that allows you to “navigate” through elements and attributes in an XML document. XPath can be especially useful when more detailed or specific searches are needed. Example: //div[@class=”content”]/p[1] performs the same function as the above CSS selector.
Other More Specific Selectors
-
ID Selectors: These selectors target elements by their unique identification attribute (ID).
-
Tag Name Selectors: These selectors target elements by the name of their HTML tag.
-
Class Selectors: These selectors target elements by their class attribute.
-
Attribute Name Selectors: These selectors target elements by the value of a specific attribute.
Obtaining XPath and CSS Selectors Using Browser Tools
Most modern browsers like Chrome and Firefox offer built-in developer tools that allow you to inspect the DOM and easily obtain selectors.
Example page: http://books.toscrape.com/
-
Right-click on the element you want to select.
-
Choose “Inspect” or “Inspect Element”.
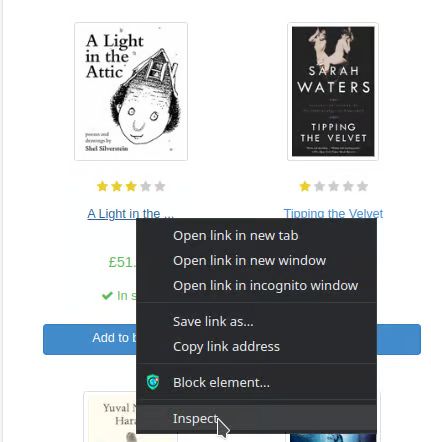
-
In the developer tools window, right-click on the highlighted element.
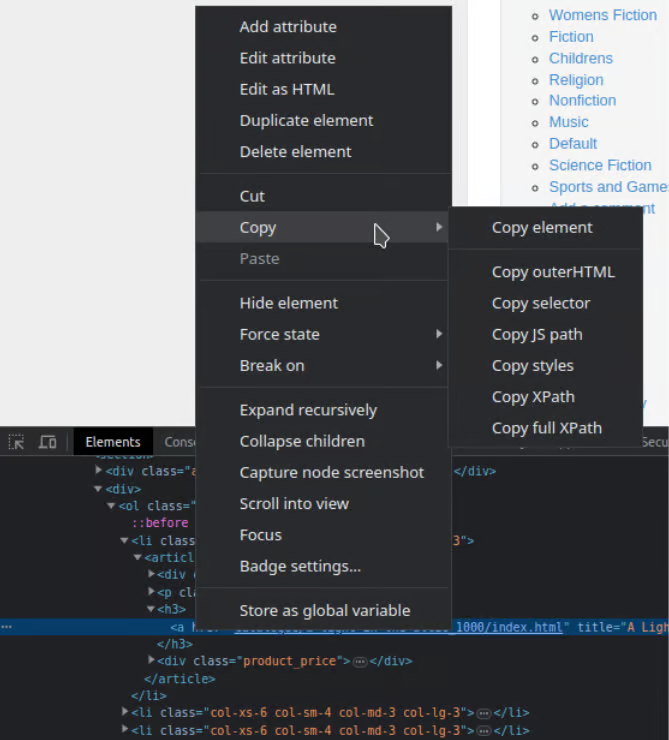
-
To get a CSS selector: Choose “Copy” and then “Copy selector”.
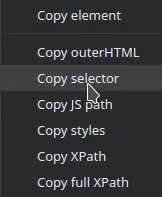
-
To get an XPath: Choose “Copy” and then “Copy XPath”.
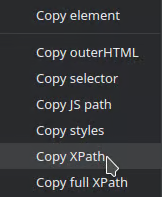
Within the same toolbox, you will have the opportunity to test both CSS selectors and XPath. To do this, simply press the Ctrl + F key combination, which will open the search function. Then, copy and paste the selector into the search bar to verify its correct functionality.
Furthermore, there is the option to create your own CSS selectors or XPath and then assess their performance in the browser’s toolbox. This process will allow you to confirm if they are operating as per your expectations.
Examples:
-
Search bar: In this toolbar, it is possible to perform searches for XPath, CSS, or other components present in the HTML code.
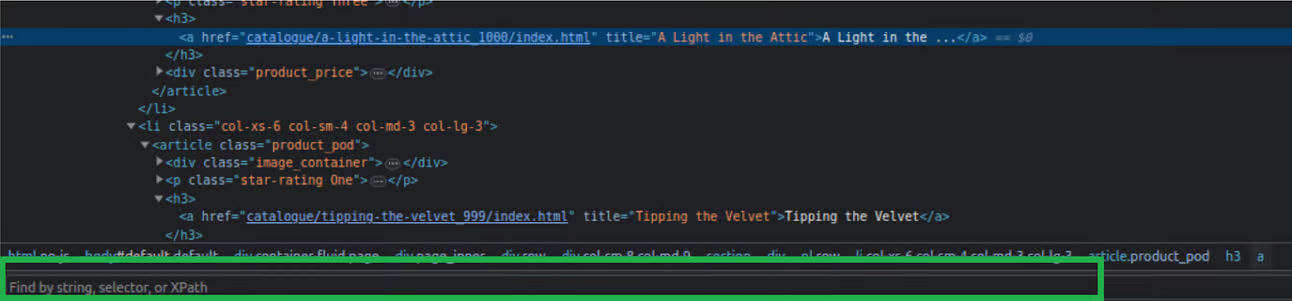
-
Pasting the default CSS selector: Through the query derived from the CSS selector, only the specified element will be extracted.
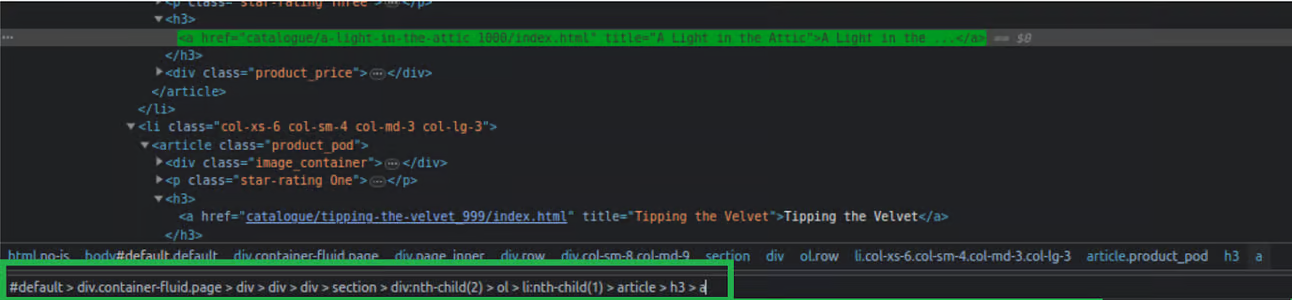
-
Own CSS selector (to select all titles): Using this modified query, all “h3 > a” elements present on the page will be returned, rather than just the previously specified element.
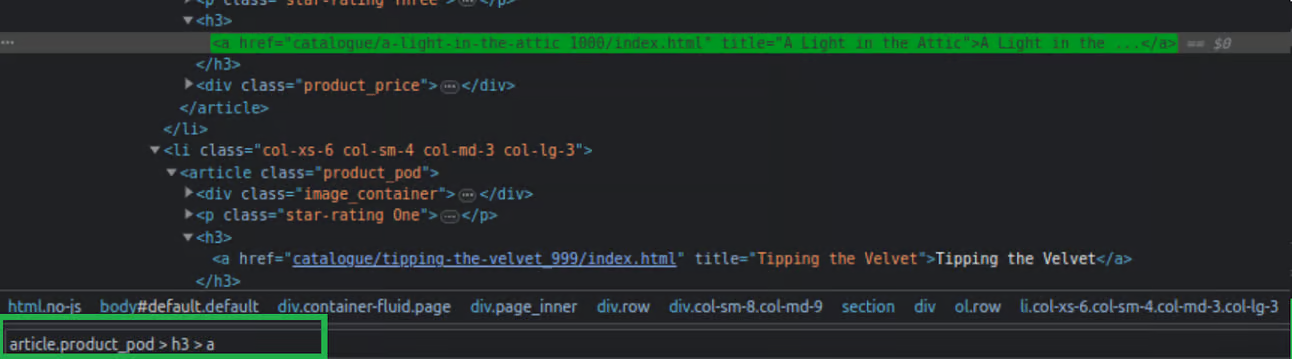
-
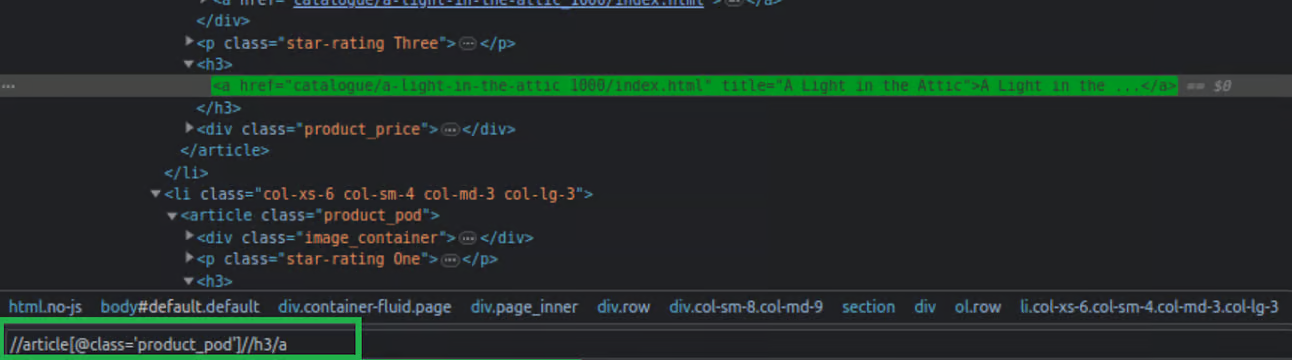
Pasting the default XPATH selector: By using the query extracted from the XPath, exclusively the designated element will be obtained.
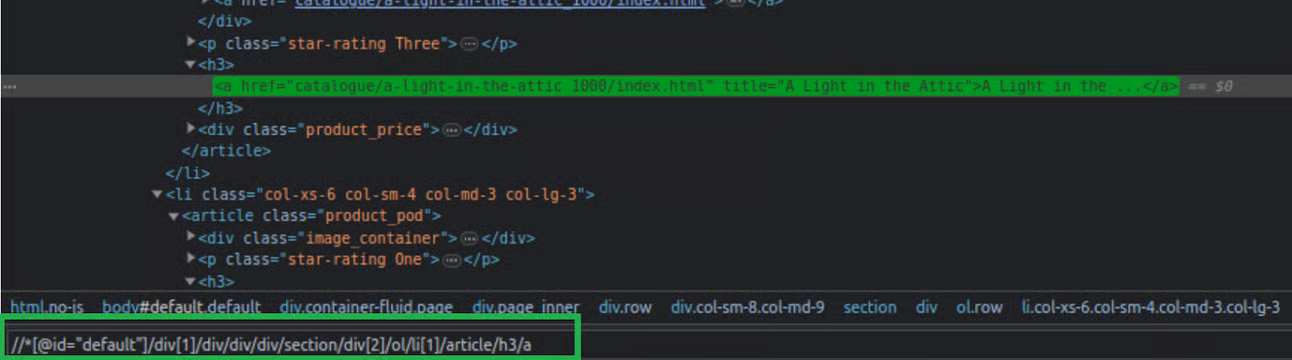
-
Own XPATH selector (to select all titles): Using this modified query, all “h3 > a” elements present on the page will be returned, rather than just the previously specified element.
If you wish to deepen your understanding of CSS and XPath selectors, I provide the following links to enrich your knowledge:
-
CSS selectors: https://www.w3schools.com/cssref/css_selectors.php
-
XPATH selectors: https://www.w3schools.com/xml/xpath_syntax.asp
Exploring the Tools
-
Scrapy: https://docs.scrapy.org/en/latest/topics/selectors.html
-
Using CSS Selectors
titles = response.css('div.content > p::text').getall() for title in titles: print(title) -
Using XPath
titles = response.xpath('//div[@class="content"]/p/text()').getall() for title in titles: print(title)
-
-
Beautiful Soup: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
-
Using CSS Selectors
from bs4 import BeautifulSoup soup = BeautifulSoup(html_content, 'html') titles = soup.select('div.content > p') for title in titles: print(title.text)
-
-
Selenium: https://www.selenium.dev/documentation/webdriver/elements/locators/
-
Using CSS Selectors
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('url_del_sitio') titles = driver.find_elements(By.CSS_SELECTOR, 'div.content > p') for title in titles: print(title.text) -
Using XPath
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('url_del_sitio') titles = driver.find_elements(By.XPATH, '//div[@class="content"]/p') for title in titles: print(title.text)
-
Conclusion
Selectors are the essence of web scraping. By mastering them and knowing how to efficiently obtain them using browser tools, you ensure that your scraping project is robust and efficient. Whether you’re using Scrapy, Beautiful Soup, or Selenium, a solid understanding of selectors will take you far in your data extraction efforts.
If you want to delve deeper into advanced web scraping techniques and how to apply them in real-world scenarios, Contact Bitmaker today, their customized web scraping solutions, and continuous monitoring will empower your business with the data-driven insights necessary to make informed decisions.
At Bitmaker we want to share our ideas and how we are contributing to the world of Web Scraping, we invite you to read our first technical article Estela OSS release