Scrapy & Requests: Diverse Tools for Diverse Needs in Estela
By Joaquin Garmendia
12 min read | July 20, 2023
Estela was designed to be an extremely flexible scraping platform. It allows the use of different technologies for each one of its components. For example, Kafka can be replaced by another queuing system such as RabbitMQ. It is also possible to use different types of databases, different engine systems instead of Kubernetes, etc.
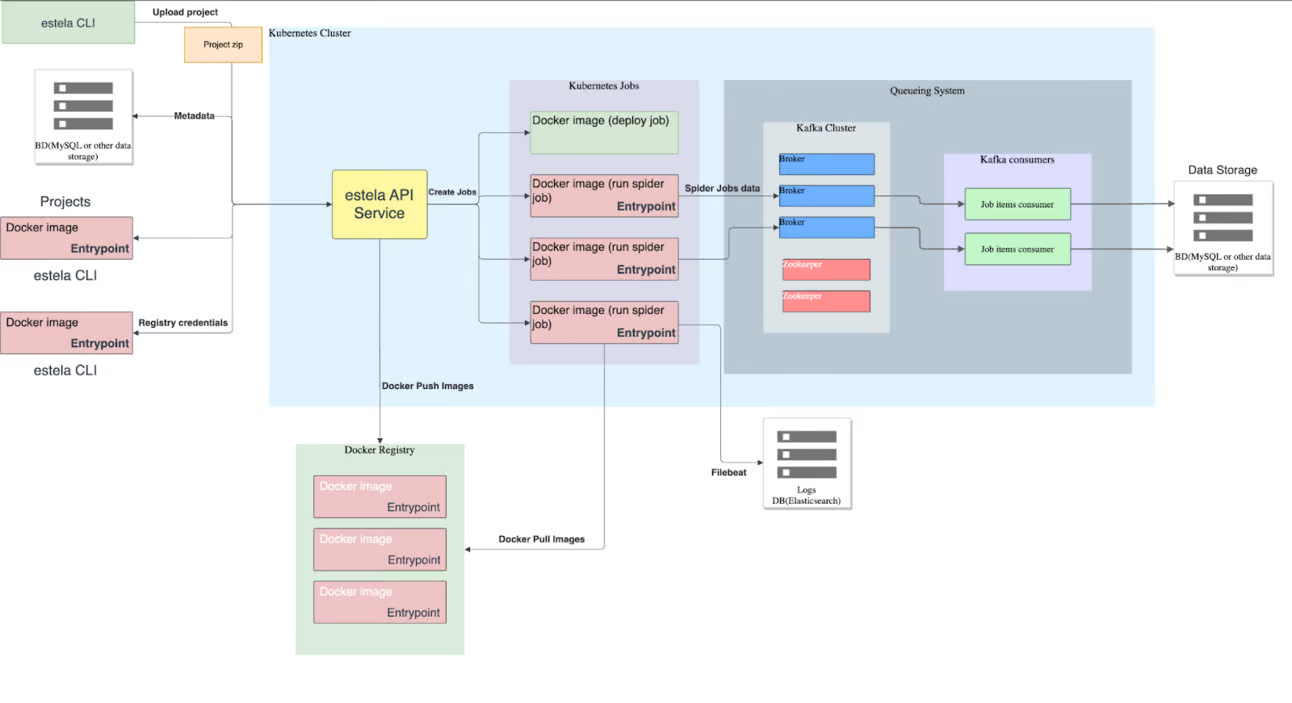
In line with this flexibility, it was logical for Estela to support different web crawling and scraping frameworks. When Estela was initially released, it only supported Scrapy spiders. Scrapy is a very specialized web scraping library, but it has a bit of a learning curve. requests, on the other hand, while not as powerful, is one of the most popular Python libraries and is very easy to use.
We are now happy to announce support for requests as a first-level citizen in Estela. The following paragraphs will explain how it was implemented and provide some examples to help developers deploy and manage request spiders in Estela.
As we are aware, Estela already supports Scrapy. Therefore, the primary question that arises while developing estela-requests is: How does Scrapy operate within the Estela framework?
Scrapy on Estela
As seen in Estela architecture image above, the spider runs within a Kubernetes pod. Estela has no knowledge of what is inside that pod; it simply runs the estela-crawl and estela-describe-project commands within this container and expects these executables to exist.
In the case of Scrapy, estela-crawl runs the scrapy crawl command, and estela-describe-project gets all the spider names in the project. These two commands (estela-crawl and estela-describe-project) are defined in the estela-entrypoint project. An entrypoint refers to the specific location in a program’s code where execution begins. In the context of the estela project the entrypoint is specifically defined within the estela-crawl component of the project.
When running estela-crawl, we need to communicate with Estela, therefore, in our entrypoint, we have middlewares and extensions to send the relevant information for Estela such as the items, logs, stats, and requests.
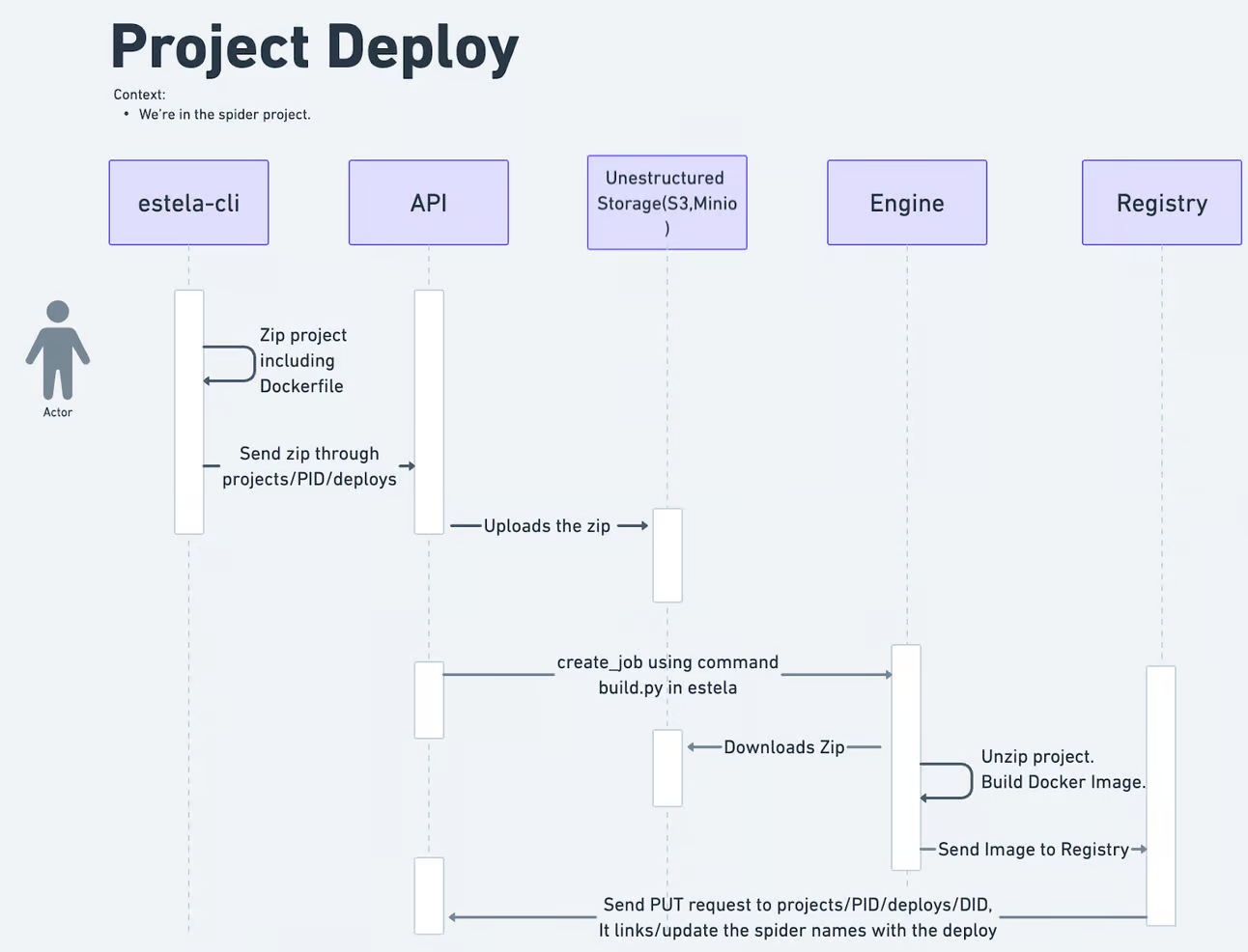
Now we need to understand the estela-describe-project command, which is necessary to deploy to Estela. Deploying a project involves many components, such as the API, Kubernetes Engine, Docker registry, etc. Deploying an Estela project is illustrated here:
To have even more context on how estela-crawl works within Estela, you can refer to this diagram:
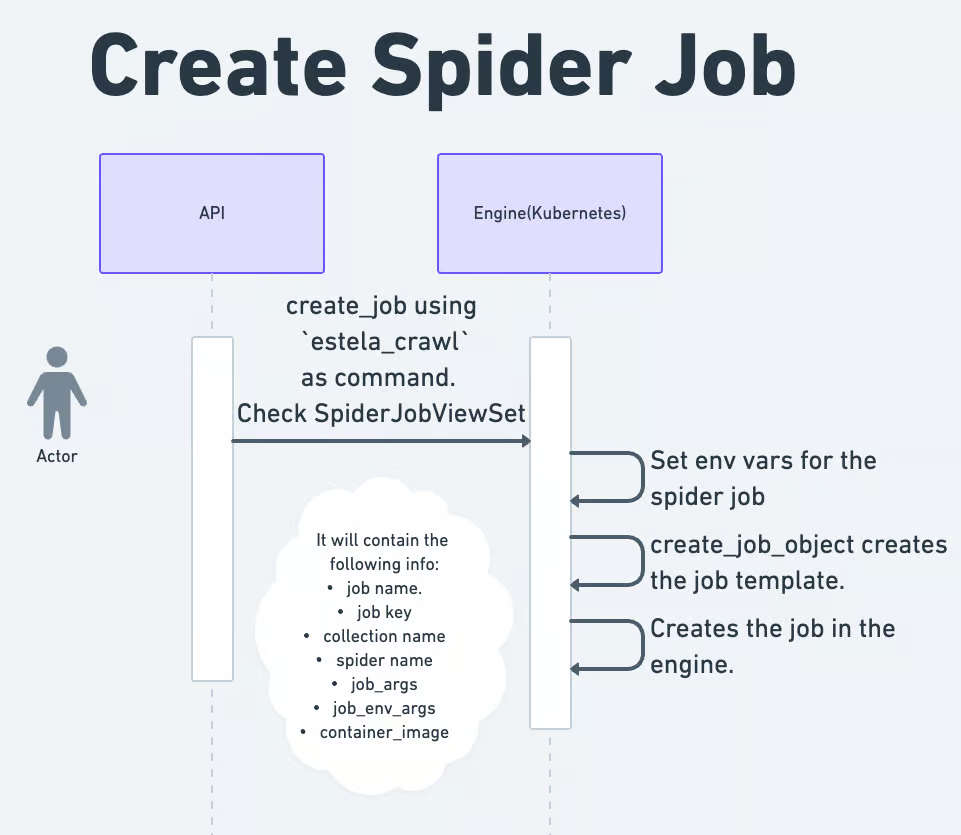
With this information in mind, we have all the necessary details to implement support for a new framework.
Implementing support for requests in Estela
It is important to note that a simple Estela entrypoint is not sufficient. This is because requests is not a web crawling framework so it’s not robust as Scrapy, which allows for extension through middlewares, item exporters, etc. Hence, to provide support for requests, two new repositories were created: estela-requests and estela-requests-entrypoint.
estela-requests is inspired by Scrapy. Just like in Scrapy, there is an object that contains all the necessary information for proper functioning. In Scrapy, it is called a “crawler,” while in estela-requests, it is called an “EstelaHub.” The EstelaHub object holds all the necessary configurations, which will be detailed later. Additionally, estela-requests include middlewares, item pipelines, and item exporters. Three initial middlewares have been introduced:
-
StatsMiddleware: Responsible for collecting statistics and sending them to Estela (via Kafka).
-
SpiderStatusMiddleware: Informs Estela when a spider runs, stops, waits or finishes.
-
RequestsHistoryMiddleware: Stores all requests made through estela-requests.
In addition to these middlewares, there’s an exporter to send the items to the database (via Kafka) when using the send_item instruction, and a log handler to send logs via Kafka to be registered in Estela.
Similar to Scrapy, estela-requests allows for code extension through middlewares, item pipelines, and item exporters. These can be defined in a settings.py file in the project’s root directory. To handle settings files we used dynaconf.
estela-requests has the following options for customization:
import logging
from Estela_requests.request_interfaces import RequestsInterface
from Estela_queue_adapter.get_interface import get_producer_interface
from Estela_requests.middlewares.requests_history import RequestsHistoryMiddleware
from Estela_requests.middlewares.spider_status import SpiderStatusMiddleware
from Estela_requests.middlewares.stats import StatsMiddleware
from Estela_requests.log_helpers.handlers import KafkaLogHandler
from Estela_requests.item_pipeline.exporter import KafkaItemExporter, StdoutItemExporter
Estela_PRODUCER = get_producer_interface() # Estela_PRODUCER is a queue producer (e.g., Kafka producer) that will be used to communicate with estela-Requests
Estela_PRODUCER.get_connection() # with Estela
HTTP_CLIENT = RequestsInterface() # HTTP Requests interface that will be used; currently, we only have RequestsInterface (requests library)
Estela_API_HOST = "" # This code will be set by Estela; you shouldn't modify it unless you want to test things
Estela_SPIDER_JOB = "" # Same as above
Estela_SPIDER_ARGS = "" # Same as above; at the moment, estela-Requests doesn't support arguments
Estela_ITEM_PIPELINES = [] # Item Pipelines to use, e.g., a DateItemPipeline that adds the timestamp to the item # Check ItemPipelineInterface to create a new item pipeline.
Estela_ITEM_EXPORTERS = [KafkaItemExporter] # Item Exporter to use, where to export or send the data # Check ItemExporterInterface to create a new exporter.
Estela_LOG_LEVEL = logging.DEBUG # Logging Level
Estela_LOG_FLAG = 'kafka' # This will be removed in future releases.
Estela_NOISY_LIBRARIES = [] # A list of noisy libraries that you want to turn off.
Estela_MIDDLEWARES = [RequestsHistoryMiddleware, StatsMiddleware, SpiderStatusMiddleware] # Middlewares to use; check MiddlewareInterface to create a new one.
JOB_STATS_TOPIC = "job_stats" # Topic name for job stats.
JOB_ITEMS_TOPIC = "job_items" # Topic name for job items.
JOB_REQUESTS_TOPIC = "job_requests" # Topic name for job requests.
JOB_LOGS_TOPIC = "job_logs" # Topic name for job logs
Currently, we use a settings.py file to customize estela-requests. However, this approach of declaring objects, classes, and so on is not ideal. In the future, our plan is to introduce settings in YAML format, which will enhance the robustness of estela-requests. It is worth noting that the http_client, which is set to default as requests, can also be customized with other HTTP clients such as curl_cffi, and so on.
The estela-requests-entrypoint repository is responsible for declaring estela-crawl and estela-describe-project. This project primarily consists of utility functions that understand the workings of the Estela engine, specifically the Kubernetes engine. It accurately maps the environment variables to the configuration of estela-requests.
The estela-crawl command executes the Python command using the subprocess library. It handles any potential errors that may arise from the subprocess and also declares a special settings.py file. This file includes all the necessary middlewares, log handlers, item exporters, and configuration required in Estela.
On the other hand, estela-describe-project locates all the spiders within the root directory, those Python scripts should include the spider_name variable. In an upcoming release, it will be expanded to include a folder called spiders/ as well.
Here is an example demonstrating how to use estela-Requests:
from bs4 import BeautifulSoup
from Estela_requests import EstelaRequests
from Estela_requests.Estela_hub import EstelaHub
from urllib.parse import urljoin
with EstelaRequests.from_Estela_hub(EstelaHub.create_from_settings()) as requests:
spider_name = "quotes_toscrape"
# Send a GET request to the website
def parse_quotes(url):
response = requests.get(url)
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the desired information from the parsed HTML
quotes = []
for quote in soup.find_all("div", class_="quote"):
text = quote.find("span", class_="text").text
author = quote.find("small", class_="author").text
tags = [tag.text for tag in quote.find_all("a", class_="tag")]
quotes.append({"text": text, "author": author, "tags": tags})
# Print the extracted information
for quote in quotes:
item = {
"quote": quote["text"],
"author": quote["author"],
"tags": ','.join(quote["tags"]),
}
requests.send_item(item)
try:
next_page = soup.find("li", class_="next").find("a").get("href")
except AttributeError:
next_page = None
if next_page:
parse_quotes(urljoin(url, next_page))
if __name__ == "__main__":
parse_quotes("http://quotes.toscrape.com/")
First, import the EstelaRequests and EstelaHub classes:
from Estela_requests import EstelaRequests
from Estela_requests.Estela_hub import EstelaHub
Once imported, you can create an EstelaRequests context manager:
with EstelaRequests.from_Estela_hub(EstelaHub.create_from_settings()) as requests:
To assign a name for the spider in Estela, declare the spider_name variable with the desired name, e.g.:
spider_name = "quotes_toscrape"
Finally, if you want to yield items, use the send_item method:
requests.send_item(item)
Deploy a requests project on estela
To deploy a requests project you can use the estela-cli, as same you can do with scrapy project, but you need to use the option -p requests. If you aren’t familiar with estela-cli, you can getting started here.
$ estela init 23ea584d-f39c-85bd-74c1-9b725ffcab1d7 -p requests
This command links your Requests project to the corresponding Estela project, allowing you to utilize Estela’s features for managing and running your project.
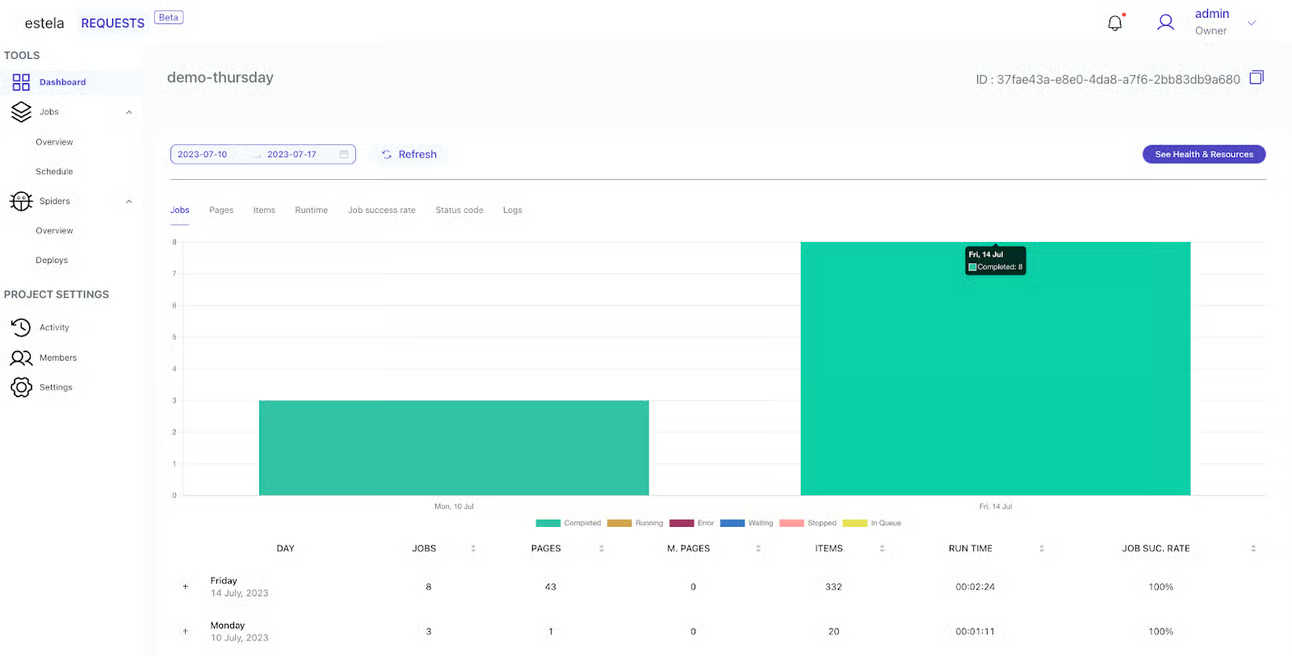
When a Requests project is launched, it is integrated within the Estela web user interface. Furthermore, it is tagged as “requests-beta”, which serves as an indicator of its beta phase and also uniquely identifies it as a project under the Requests category.
Conclusions
-
Estela is designed to be a highly flexible platform, as evident from its architecture, which allows the use of different technologies for each component.
-
Support for different web crawling frameworks in Estela is very important to serve the needs of web scraping developers using diverse tools.
-
estela-requests, inspired by Scrapy, provides a similar structure with middlewares, item pipelines, and item exporters for efficient web crawling.
-
The estela-describe-project command identifies spiders in the root directory, with plans to expand to include a dedicated spiders/ folder in future releases.
-
estela-requests allows customization through a settings.py file, which will be further improved with the introduction of YAML settings in the future.
-
Estela’s architecture enables easy extension, allowing developers to integrate other HTTP clients and technologies like curl_cffi or new scraping frameworks that use AI/LLM models.
Together with Estela, we can harness the power of web scraping and transform your organization, contact Bitmaker today to achieve significant changes.
Future work
We are testing various Python requests-like libraries that can seamlessly work with estela-requests by extending it through the settings.py configuration. As part of this effort, we have developed a proof of concept using scrapeghost, a new crawling library that leverages GPT-3.5 and GPT-4 to create spiders. In an upcoming technical article, we will delve deeper into scrapeghost + Estela. Stay tuned!
And of course, we will continue to add support for more scraping technologies into Estela, and we welcome any contributions from the scraping community.
If you are interested in this world of web scraping and how we can collaborate, we invite you to read the following article: Why Businesses Need Bitmaker’s Web Scraping Services: An Introduction to the Importance of Data Extraction.